For my PhD project, I want to use Supervised Machine Learning (SML) to replicate my manual coding efforts onto a larger data set. That means, however, that I need to put in some manual coding effort before the SML algorithms can do their magic!
I used a number of programs already to analyse texts by hand, and they all come with their up- and downsides.
A while ago I already coded articles in order to train an SML algorithm and did so having a PDF with the text opened on the left side of my screen and an Excel file with my category system on the right side.
This had the advantage that data was easily passed into R, where I did the analysis itself.
This was, however, relatively inconvenient, since the PDF took half of my screen, which meant I had to scroll back and forth in the Excel sheet.
Additionally, whenever I went back to a text to check how I used one of the categories I had to basically re-read it since I did not know any more which part of the article led me to classify it in a certain way.
The next time around, I used https://www.qcamap.org/ which is a free online content analysis application. The advantage of this was that it is meant for content analysis and so has a few useful features like the possibility to easily annotate chunks of text and label them based on the coding scheme.
A downside of qcamap, as with many other programs, is the integration with R or other programs that might be used for the machine learning part.
All newspaper articles I wanted to analyse back then were already in R, but I had to save them in individual txt files again (and in UTF-8 encoding) since this is the only format supported for import into qcamap.
When I was done coding, re-import of the data into R had again to go through an intermediate file, although this time it was relatively easy as qcamap employs the CSV file format.
This does not mean that I didn’t like qcamap specifically. I think the authors of the program have done a great job setting it up and I appreciate that the service is completely free. Neither do I think that is worse than other, often rather expensive tools (except for the requirement of individual UTF-8 txt files maybe).
Enter ‘Discourse Network Analyzer’ (DNA)
Last year I worked with Philip Leifeld on extending a software suite (a Java GUI and R package) he initially developed for people to use his method discourse network analysis—which combines (manual) content and network analysis.
However, while extending and re-writing the manual and some R functions, I realised that the software was also pretty powerful for other content analysis work.
Specifically, I think ´DNA´ has three advantages:
1. Its integration into R is pretty good.
You can pass documents into the database via dedicated functions in its companion package ‘rDNA’ (which I helped to develop) and you can retrieve data, either again via ‘rDNA’ or directly from the SQLite database.
2. It has some surprisingly useful functions for content analysis that I did not find in any other content analysis software so far: Regex highlighting and Regex search.
Since the two most important words for my analysis were “protest” and “demonstration” I could simply use the Regex “protest|demonstrat” to both highlight the terms (in any RGB colour I like!) or go through the documents using the search function.
3. It’s not just free, but also completely open-source.
That means you can check out the source code at any point on: https://github.com/leifeld/dna You can also submit bug reports, request a feature or contribute code via your own pull request.
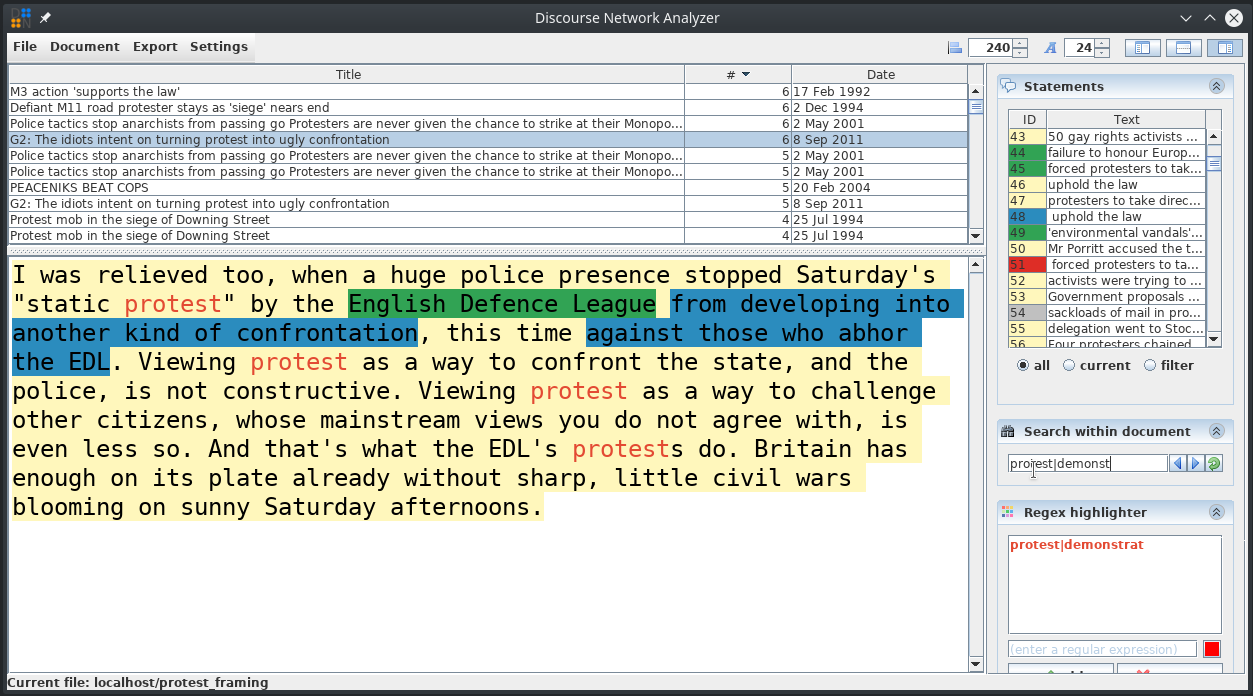
Even though ´DNA´ was developed for using it with a specific method (discourse network analysis) and I won’t be using that for now in my PhD, I think that at least for me it is the best choice. It combines the possibility to highlight text chunks and sort them into categories and provides a few nice features on top of that. The category system is set up for doing discourse network analysis by default and ‘rDNA’ makes the workflow with this method very easy. However, this does not mean the program can’t be used for other content analytical tasks and might be better for them than many of the available tools as well.